
Event Loop in Node.js

Introduction
This article helps you to understand how the Node.js Event Loop works, and how Node.js handles asynchronous operations although it runs on just one thread.
What is Node.js
Before the event loop, I'd like to start with what exactly Node.js is and what abilities it provides us. Node.js explains itself as below;
Node.js is a Javascript runtime built on Chrome's V8 JavaScript engine. Node.js uses an event-driven, non-blocking I/O model that makes it lightweight and efficient.
Firstly we should know that Node.js is not a programming language, it's a runtime environment for executing javascript code and built on the V8 engine. Node.js lets us use javascript for server-side operations e.g. fetching user information from the database or importing some files to S3.
 Image Credits: Andrew Mead’s course
Image Credits: Andrew Mead’s course
Let's focus on what the non-blocking I/O model means and how it makes our applications lightweight and efficient. I/O means input/output process and it can be anything you can think of e.g. calling API with HTTP or consuming some data from SQS. Let's check it out in the example below.
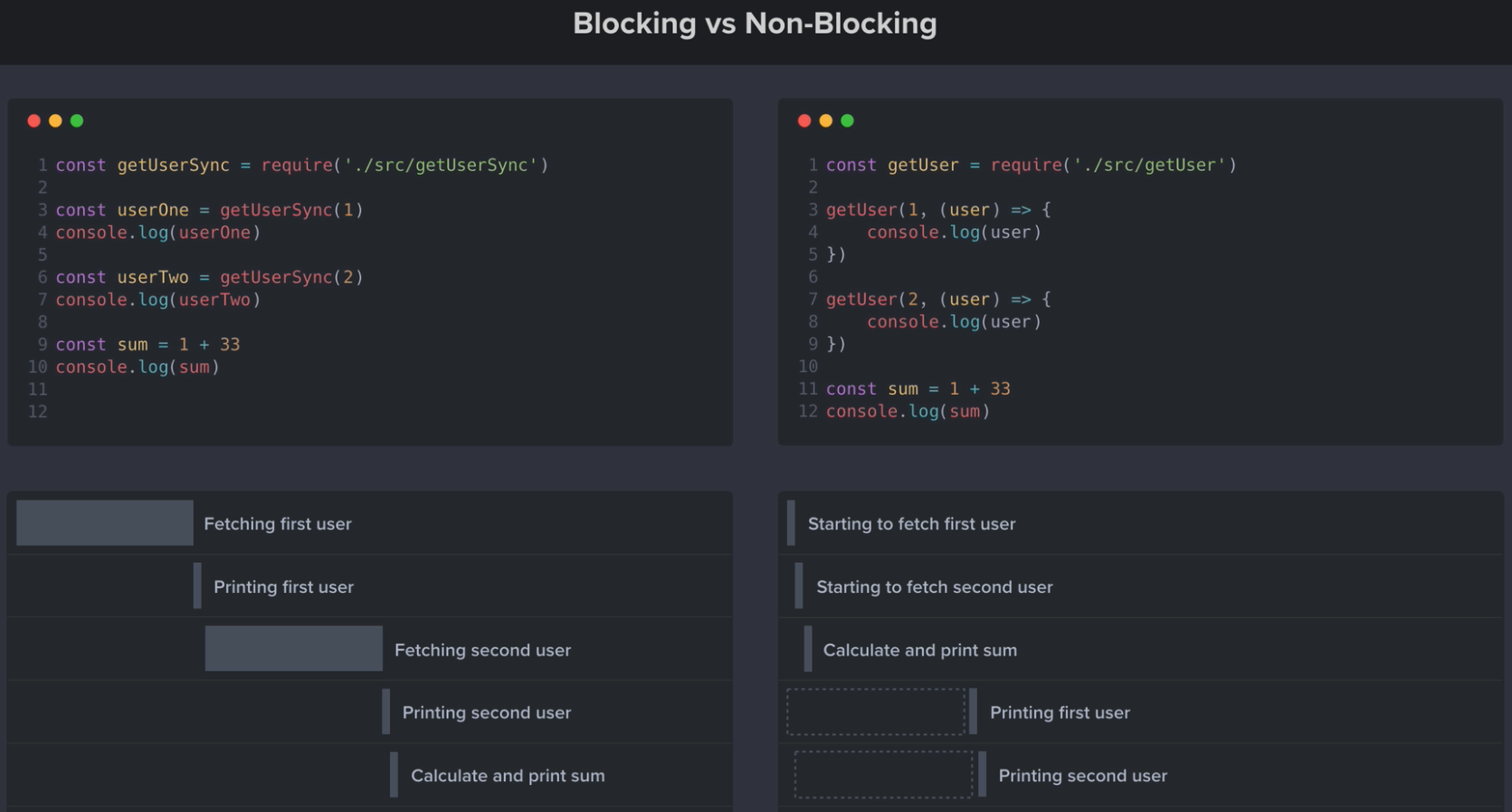 Image Credits: Andrew Mead’s course
Image Credits: Andrew Mead’s course
There are two types of models: blocking and non-blocking and each model has three different processes;
- Fetching user one
- Fetching user two
- Sum of two number
The blocking model waits for the previous line process to finish to execute a new line and it hangs during this time. The problem with this is that our third process, the calculating sum of two numbers, has no dependency on the user fetching process but the program spends time waiting for the fetches to complete before returning that result. Imagine if all processes for your application worked like that...
Compare this with the non-blocking model, here we process the first line and instead of waiting for the user fetch to complete before moving to the second line, we throw an event "get user one" and the process starts running in the background. The same happens for the second user fetch and so the user first sees the result of the sum on the screen. After the background processes are finished the user sees the information about the users appearing. There is no guarantee that user number one’s data will drop first on the screen although the event that calls it is thrown first. That result can differ every time the code runs and depends on many things e.g. network speed, the data size of the user and more.
As this example demonstrates, non-blocking is more efficient than blocking two times. It's a perfect way to speed up our application, but how does Node.js handle those processes asynchronously in the background without affecting end-users and screens?
Event Loop
The Node.js JavaScript code runs on a single thread unlike other famous programming languages e.g. C# Java. However, we can use the asynchronous approach as we saw in the example above. We have just a single thread but we can perform multiple tasks at the same time. We should know the event loop mechanism in Node.js to understand how it's possible.
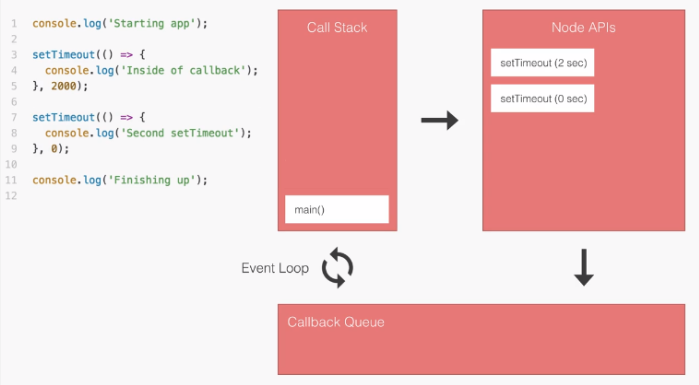 Image Credits: Andrew Mead’s course
Image Credits: Andrew Mead’s course
Call Stack
The node js call stack is a typical LIFO queue (Last In First Out). It is responsible for tracking all operations in our program.
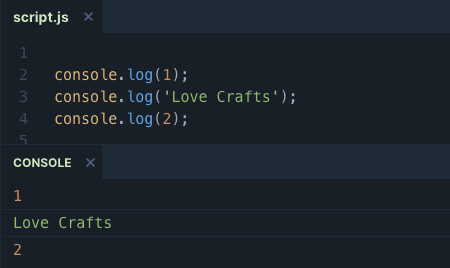 Image Credits: Andrew Mead’s course
Image Credits: Andrew Mead’s course
Imagine that we have three different log operations in our application and we see the result like the image above. Firstly, the first operation goes into the stack and waits to be executed. Thankfully log is a really simple operation and it's executed so quickly that we can see the result in our console and the operation leaves the stack. The process continues to work like that for the second and third operations.
Node API and Callback Queue
In the previous example, we saw how the call stack works for synchronous operations. What if we have an operation that needs to fetch some data from the database? Again will the call stack wait until the operation is finished? The answer is no because we have the Node API and Callback Queue.
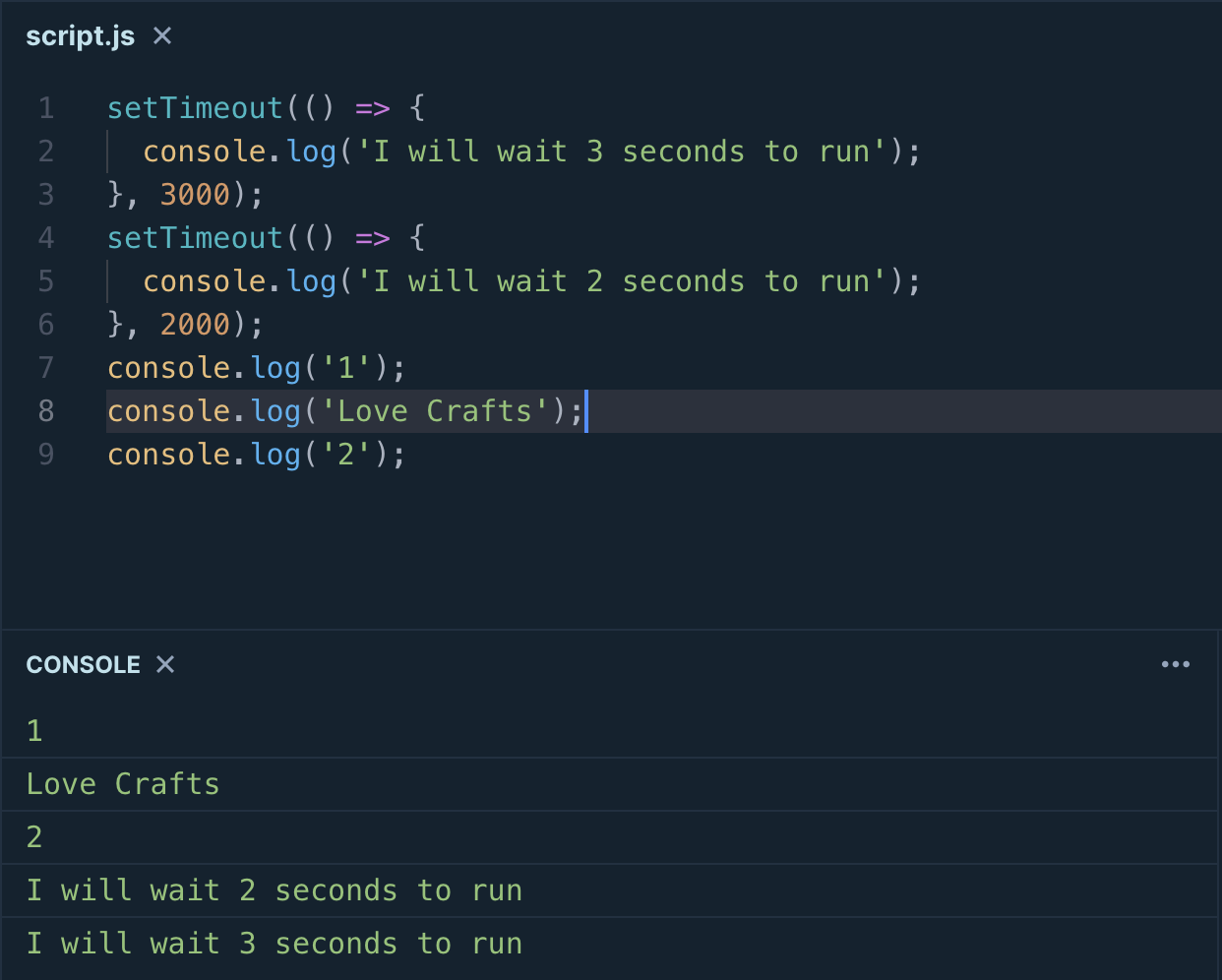
We have added two new operations that are not synchronous. As you can see from the image, they are the last two items in the console although they are first and second in the code.
Again our application starts and the first operation goes into the stack but it is setTimeOut function that is not part of the JavaScript Programming Language. So the operation is sent to the Node API and waits three seconds. This operation mimics waiting for a database request to complete. The second operation is again setTimeOut so it goes to Node API and waits two seconds. The remaining operations go into the stack line by line and they go out from the stack after they are executed.
After Node API finishes the process, it always checks whether the stack is free or not. Those results wait for the stack to be empty in the Callback Queue. In this example, the second setTimeOut operation is the first item in the queue because it waits two seconds, not three.
Conclusion
In this article, we showed how Node.js handles asynchronous operations although it runs on a single thread. Now you should understand why the two-second time delay function does not block the rest of the program from executing. I hope you enjoyed reading this article and learned something new.

