

I'd like to talk about a topic in functional programming that is practically useless to the average developer, but I think nonetheless really fascinating. This post originated as a chapter in a book I wrote a long time ago, which became a presentation with slides which I've given a few times, and this is the third iteration of that, so hopefully, I've ironed out some of the lumps and bumps by now.
So what are continuations? Continuations are an advanced control flow technique in functional programming, mostly used in the implementation of programming languages. They allow fairly trivial ways to implement things like non-local return, threads, generators/yield etc., but understanding them requires a bit of background, so I'll try to do that first.
Functional Programming
First off, what do I mean by functional programming? Simply put, functional programming bans the use of the assignment operator =. That's it. The only way a variable can get a value is as an argument to a function, and so the only place a variable can be declared is as a formal argument to a function. Voluntary submission to this discipline means that there can be no side effects anywhere in your code, and calling the same function with the same arguments will always return the same result.
Stack Frames
Hopefully, we're familiar with the basic idea of a stack, a "last-in, first-out" data structure. But you may be less familiar with how stacks are used to cope with function calls, arguments, return values, and return statements in a programming language.
Within such a "stack-based" language, when one function calls another, the arguments to the function and the return address (address of the instruction after the call) are pushed onto an internal stack, followed by a count of the number of arguments. This block of data is called a stack frame. Having pushed the new stack frame, the language then does a GOTO the first instruction in the body of the called function. When the function is done, it writes its return value into the stack frame and does a GOTO the return address. At that return address, the final bit of code recovers the return value and restores the stack to its previous state.
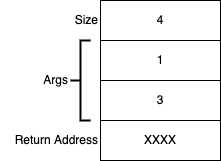 an example stack frame.
an example stack frame.
Of course, in practice things are a bit more complicated; the implementation will prefer the CPU registers over the stack for passing and returning arguments, and only "spill" registers onto the stack when necessary; there may be no need to record the size of the stack frame, etc. but in the simplest case, the description above is correct.
Tail Call Optimisation
Before we can get to continuations, we need to discuss the somewhat related topic of tail call optimization (TCO, sometimes called tail call elimination), which is a way to avoid unnecessary use of stack when making function calls.
Look at this implementation of factorial:
function factorial(n) {
if (n === 0) {
return 1;
}
return n * factorial(n - 1);
}
(I'm using javascript, which is the language de jour around here.) The factorial of 0 is 1, otherwise the factorial of n is n times the factorial of n - 1. factorial is undefined for negative numbers.
In this version of factorial, there are deferred computations. Specifically, each multiplication by n can't be done until the recursive call to factorial has returned. Imagine how the stack behaves in this implementation on a call to factorial(5):
factorial(5)
5 * factorial(4)
5 * 4 * factorial(3)
5 * 4 * 3 * factorial(2)
5 * 4 * 3 * 2 * factorial(1)
5 * 4 * 3 * 2 * 1 * factorial(0)
5 * 4 * 3 * 2 * 1 * 1
5 * 4 * 3 * 2 * 1
5 * 4 * 3 * 2
5 * 4 * 6
5 * 24
120
All those multiplications have to wait until factorial(0) finally returns, and then the result is calculated on the way back out.
We can rewrite factorial so that there are no deferred computations with a helper function like this:
function factorial(n) {
return factorialHelper(n, 1);
}
function factorialHelper(n, a) {
if (n === 0) {
return a;
}
return factorialHelper(n - 1, n * a)
}
In this version of factorial, the last thing factorialHelper does is to call itself, and it immediately returns the result. It can do this because of that extra argument a, an accumulator that holds the result so far. In this version, the result is calculated on the way up the stack, and when factorialHelper is called for the last time it already has the result:
factorial(5)
factorialHelper(5, 1)
factorialHelper(4, 5)
factorialHelper(3, 20)
factorialHelper(2, 60)
factorialHelper(1, 120)
factorialHelper(0, 120)
120
120
120
120
120
120
120
Calling a function and immediately returning the result is known as a tail call, and such function calls are said to be in tail position. Functions which call themselves in tail position are called tail-recursive.
Tail calls do not need a stack!
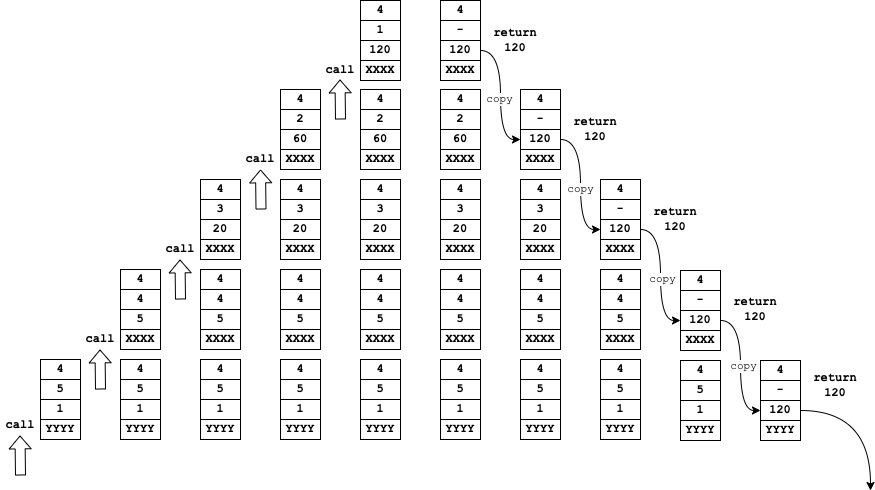
If you think about the original non-tail-recursive version of factorial, it has to push a new stack frame for each recursive call, containing the decremented version of n, because it needs to keep a record of its own un-decremented value of n in the current stack frame in order to multiply it by the result of the recursive call before returning it.
But in the tail-recursive version, factorial does not need to remember the value of either n or a because when the recursive call returns the result of that call is already the final result of the function.
So instead of pushing a new stack frame and calling the recursive function, it can just replace the values of n and a in the current stack frame and goto the factorial function.
When this function finally does a return (by popping the stack frame and doing a goto the return address it contained) it returns directly to the original caller of factorial.
That is to say, instead of doing all of this:
We can just do this:
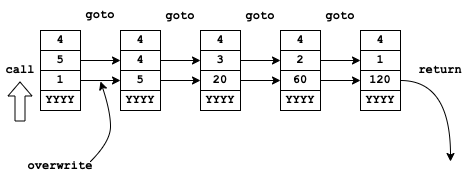
And our recursive factorial procedure is now iterative:
factorial(5)
factorialHelper(5, 1)
factorialHelper(4, 5)
factorialHelper(3, 20)
factorialHelper(2, 60)
factorialHelper(1, 120)
factorialHelper(0, 120)
120
That is tail call optimisation. It can be done for all tail calls, not just recursive ones and it transforms tail-recursive functions into iterations, which operate in a fixed space and consume no stack.
However, while TCO solves the problem for our second factorial implementation, it does not help our first, because in that case, the recursive call is not in tail position.
Continuations, Finally
As I've said, continuations are an advanced control flow technique that simplifies the implementation of many other types of control flow in a programming language implementation. Continuations are used by writing in what is known as Continuation Passing Style (CPS.) To understand CPS there's only one thing you need to remember:
In Continuation Passing Style no function you call ever returns!
Think about that for a minute. I mean how do you get a result from a function if it never returns?
The answer is you pass it an extra argument, a closure of one argument that takes the result of the function and does what you were going to do with it. This extra argument is called the continuation of the function, it's what the code does next.
Example: Factorial Again
Let's return to our original factorial function and try to re-write it into CPS.
function factorial(n) {
if (n === 0) {
return 1;
}
return n * factorial(n - 1);
}
console.log(factorial(5));
This example logs the result to the console so let's start by passing a continuation to do that:
factorial(5, r => console.log(r));
Next, we know that factorial takes an extra argument continuation, so that's also pretty simple:
function factorial(n, c) {
And we know that instead of returning a result, factorial must call its continuation on its result, so the next few lines are also pretty simple:
function factorial(n, c) {
if (n === 0) {
c(1);
}
This already works for factorial(0), it will print 1.
Now we come to the tricky bit:
return n * factorial(n - 1);
It often pays when converting code into CPS to break down complicated expressions into simpler steps. Here we'll introduce a temporary variable, not good functional programming but the temp will disappear again later:
const v = factorial(n - 1);
return n * v;
Now it's clear that factorial is called first, then its result is multiplied by n.
We know that we can't return the value of n * v, we must instead call our continuation on it:
const v = factorial(n - 1);
c(n * v);
Finally, we know that the recursive call to factorial isn't coming back, so we need to pass it a continuation to do what we were going to do with the result:
factorial(n - 1, v => c(n * v));
And we're done!
function factorial(n, c) {
if (n === 0) {
c(1);
} else {
factorial(n - 1, v => c(n * v));
}
}
factorial(5, r => console.log(r)); // prints 120, try it.
Note I needed to add the else because javascript is actually going to return from c(1) eventually and we'd have unterminated recursion otherwise.
We can rewrite our alternative tail-recursive factorial too:
function factorial(n, c) {
factorialHelper(n, 1, c);
}
function factorialHelper(n, a, c) {
if (n === 0) {
c(a);
} else {
factorialHelper(n - 1, n * a, c); // TCO
}
}
factorial(5, r => console.log(r));
What's interesting here is that there is another kind of tail call optimisation going on. Because there is no deferred computation, there is no need to pass a new continuation to the recursive call to factorialHelper just to call the argument continuation (like v => c(v)); Instead, we can just pass the argument continuation c directly.
Standard CPS Formulae
Passing one function as an argument to another is not in itself particularly novel, what's special about CPS is that it takes that idea to the logical extreme. Another thing about CPS is that all the transforms that must be made to convert code into CPS are local (they can be done without having to look outside of the function being transformed) and mechanical (they can be automated by an IDE or a compiler.) In this section, we'll take a quick look at the standard transforms and fill in the gaps that were left by our factorial examples above.
Example 1. One function returns the result of another.
function x() {
return y();
}
becomes:
function x(c) {
y(c);
}
Instead of returning the result of calling y(), we just pass our continuation to y(), effectively saying "y() put your result here".
Example 2. One function calling another, passing it the result of a third
function x() {
return y(z());
}
This time there is deferred computation so we need to pass a new continuation to call y() with the result of z() (and x()'s continuation).
function x(c) {
z(v => y(v, c));
}
Example 3. Conditionals
function w() {
if (x()) {
return y();
} else {
return z();
}
}
Since x is not coming back, we need to pass it a continuation that contains the actual conditional:
function w(c) {
x(v => v ? y(c) : z(c));
}
Example 4. Loops
Loops must be re-written as recursions, then the standard CPS transforms can be applied to them.
Connection to TCO
Tail Call Optimisation can only apply to function calls in tail position. What makes it particularly relevant to CPS is that in CPS all function calls are in tail position! It's quite obvious if you think about it, to convert to CPS we wrap everything after a function call into a continuation and pass that to the function, so there is no code after the call to the function, and by definition that call is now in tail position.
So by combining TCO and CPS, the stack is replaced by the continuation chain.
However, not all languages support TCO. It turns out that continuations themselves provide an alternative to TCO, more on that later.
Applications
So now we know what continuations are, but we haven't looked at what they can be used for.
Probably the best way to think about a continuation is that it is a variable that holds the function's return statement. But since it's a variable, it can be treated like any other first class data. It can be stored for later retrieval, passed from function to function, and called from anywhere. Let's look at an example.
function a() { m(); x(); }
function m() { n(); }
function n() {}
function x() { y(); }
function y() {}
a();
you can see that a() calls m() which calls n(), then a() calls x() which calls y(). To labour the point (it will be important later) here's a diagram of that flow.
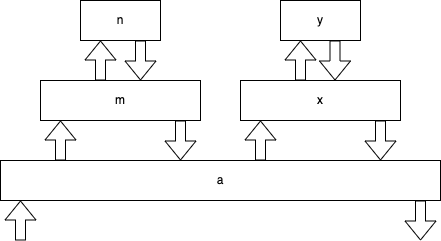
Lets's add some debug
function p(s) { console.log(s); }
function a() { p('a'); m(); p('a'); x(); p('a'); }
function m() { p('m'); n(); p('m'); }
function n() { p('n'); }
function x() { p('x'); y(); p('x'); }
function y() { p('y'); }
a();
you can run this or just by inspection convince yourself that it will print the sequence "a", "m", "n", "m", "a", "x", "y", "x", "a". Now let's rewrite that into CPS:
function p(s) { console.log(s); }
function a(c) {
p('a');
m(() => {
p('a');
x(() => {
p('a');
c();
});
});
}
function m(c) {
p('m');
n(() => {
p('m');
c();
});
}
function n(c) {
p('n');
c();
}
function x(c) {
p('x');
y(() => {
p('x');
c();
});
}
function y(c) {
p('y');
c();
}
a(() => {});
There's nothing here we haven't seen before, the only differences are that I haven't bothered rewriting the debugging calls to p() to CPS, and since we're not returning anything useful the continuations don't take any arguments. If you run this you will see that it prints exactly the same "a", "m", "n", "m", "a", "x", "y", "x", "a" sequence and therefore exhibits the same control flow.
Now let's make just three changes:
let s; // CHANGE 1.
function p(s) { console.log(s); }
function a(c) {
p('a');
m(() => {
p('a');
x(() => {
p('a');
c();
});
});
}
function m(c) {
p('m');
n(() => {
p('m');
c();
});
}
function n(c) {
s = c; // CHANGE 2
p('n');
c();
}
function x(c) {
p('x');
y(() => {
p('x');
c();
});
}
function y(c) {
p('y');
s(); // CHANGE 3
}
a(() => {});
In change 1 we declare a global variable s, in change 2 function n() assigns its continuation to s, and in change 3, function y() calls the continuation s() instead of its own continuation c(). Can you guess what this is going to print? It prints "a", "m", "n", "m", "a", "x", "y" as before, but then instead of finishing up with , "x", "a" it prints "m", "a", "x", "y" repeatedly, until you run out of stack (without TCO).
We have changed control flow to this:
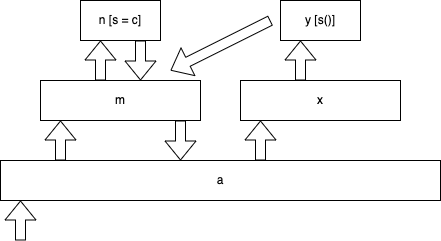
Since y() is returning through n()'s continuation, it returns to the same spot in the code that n() returns to!
Note that this is real non-local return, it's not just like a throw/catch where the catch is "beneath" the throw and still waiting for it, function m() had already returned at the point of the non-local return and it's like we are going back in time to an arbitrary prior point in the process flow.
It should be apparent that we can do a lot with this, being able to jump back to a previous location that is no longer executing is at the heart of generator functions for example.
If javascript had continuations accessible, by i.e. taking a reference to the return statement, then we could rewrite our pre-CPS version like this:
// this is not valid JavaScript - it is just an illustration.
let s; // CHANGE 1
function p(s) { console.log(s); }
function a() { p('a'); m(); p('a'); x(); p('a'); }
function m() { p('m'); n(); p('m'); }
function n() {
s = \return; // CHANGE 2
p('n');
}
function x() { p('x'); y(); p('x'); }
function y() {
p('y');
s(); // CHANGE 3
}
a();
And this would also print "a", "m", "n", "m", "a", "x", "y", "m", "a", "x", "y", "m", "a", "x", "y"...
FP purists may object to that variable
sin the examples above, I realise to write functionallyn()would have had to return it's continuation tom()(by calling it likec(c)) thenm()would return it toa()which would pass it tox()which would pass it toy(). I thought it better to keep the example simple rather than pure.
The Trampoline
As mentioned previously, some languages don't support TCO which makes using CPS in those languages apparently impractical. However CPS itself provides a solution to this. The thing to realise is that we're no longer using return, but it's still there, and we can re-purpose it.
The idea is that wherever we were calling any function or continuation, which in the absence of TCO will eat stack, we instead return a closure of zero arguments (a "promise") which will call the function or continuation for us, and a special routine called a "trampoline" repeatedly invokes those promises until they return null.
It's honestly easier to write than it is to describe, here it is:
function trampoline(promise) {
while (promise) {
promise = promise();
}
}
(Note that this may or may not be exactly the same thing as Javascript's promises ;-).
Let's re-visit our favourite factorial function after transformation to CPS
function factorial(n, c) {
if (n === 0) {
c(1);
} else {
factorial(n - 1, v => c(n * v));
}
}
factorial(5, v => console.log(v));
and now let's rewrite it to use that trampoline:
function trampoline(promise) {
while (promise) {
promise = promise();
}
}
function factorial(n, c) {
if (n === 0) {
return () => c(1);
}
return () => factorial(n - 1, v => c(n * v));
}
trampoline(() => factorial(5, v => { console.log(v); return null; }));
Note the differences, instead of just calling c(1) we return () => c(1); for the trampoline to call, and instead of calling factorial(n - 1, v => c(n * v)) we return () => factorial(n - 1, v => c(n * v)) for the trampoline to call.
This only uses three stack frames: one for trampoline itself, one for the current promise, and one for the function that promise calls. Also note that because we return null to the trampoline to terminate it in the outermost continuation, that call to c(1) really isn't coming back so we can loose the else that was guarding the recursive call to factorial.
Threading with a Trampoline
The trampoline is already managing a single thread of computation (the chain of promises.) It can manage more than one:
function trampoline(queue) {
while(queue.length) {
const promise = queue.pop();
const result = promise();
if (result) {
queue.unshift(result);
}
}
}
Here instead of a single thread (promise) the trampoline takes a queue of them. While there are threads on the queue it pops the first one from the front, executes it, and if it gets a promise back (non-null result) it pushes the result on to the back of the queue.
We can demonstrate that threading trampoline in action with some simple code that doesn't even use continuations:
function x() {
console.log('x');
return x;
}
function y() {
console.log('y');
return y;
}
trampoline([x, y]);
Obviously this will print "x", "y", "x", "y", "x", "y" etc. ad infinitum. While this example doesn't use continuations, for this technique to be generally useful we need them: because we've re-purposed return to run our trampoline, we've no way other than continuations to get access to the results of function calls.
Example: CPS factorial with a threading trampoline
Let's put this all together, we can use the same trampolined version of factorial we wrote earlier, and combine it with the threaded trampoline above, the only addition is some debug so that we can see it working:
function trampoline(queue) {
while(queue.length) {
const promise = queue.pop();
const result = promise();
if (result) {
queue.unshift(result);
}
}
}
function factorial(id, n, c) {
console.log(id, n);
if (n === 0) {
return () => c(1);
}
return () => factorial(id, n - 1, v => c(n * v));
}
trampoline([
() => factorial("a", 2, v => { console.log("a =", v); return null; }),
() => factorial("b", 2, v => { console.log("b =", v); return null; })
]);
This prints the following:
b 2
a 2
b 1
a 1
b 0
a 0
b = 2
a = 2
So threads "a" and "b" are demonstrably alternating.
Preemptive Versus Cooperative Multi-tasking
The previous section showed how the trampoline can be used to switch between different threads of computation. That is precisely what multi-tasking is, however it is a specific type of multi-tasking that does not give the threads control over when they run. This kind of multi-tasking is called preemptive multi-tasking since the trampoline preempts the execution of a thread arbitrarily. This can cause problems, especially outside of a purely functional environment where shared variables can change state. However it's exactly the kind of multi-tasking that you want from say an operating system, to fairly share resources between isolated processes.
An alternative to preemptive multi-tasking is cooperative multi-tasking. In cooperative multi-tasking the threads themselves decide when to relinquish control. This is more like the Javascript idea of a thread and this is surprisingly easy to implement too, with only a couple of tiny changes to the trampoline:
const queue = [];
// ...
function trampoline() {
while(queue.length) {
let promise = queue.pop();
while (promise) {
promise = promise();
}
}
}
Note the differences, firstly the queue is external to the trampoline. Also in this case the promise is popped off the queue then repeatedly executed until it returns null, just like the original trampoline we looked at. However because the queue is global, it is accessible to the threads being managed by the trampoline. Any thread wishing to relinquish control need only put its continuation on the back of the queue itself, then return null to the trampoline, giving us a very basic yield-like implementation:
function yield(c) {
queue.unshift(c);
return null;
}
Which you'd call like any other trampolined function as
return () => yield(c);
Spawn and Exit
When the queue is global, we can do other things than just relinquish control, we can also create and destroy new threads. For example this function:
function spawn(c) {
queue.unshift(() => c(true));
return () => c(false);
}
returns false to its caller (through it's argument continuation) in the current thread, but also creates a new thread at the back of the queue where it returns
true to its caller.
Again you'd call it like
return () => spawn(c);
To complement that we'll need to be able to terminate a thread. This little function does just that:
function exit(c) {
return null;
}
called like
return () => exit(c);
Putting those together we can write this kind of thing (first without CPS which won't work but lets you see the intention)
// n.b. not intended to actually work
function x() {
if (spawn()) {
console.log("hello");
} else {
console.log("goodbye");
exit();
}
}
Then re-written into CPS where it will work:
function x(c) {
return () => spawn(
v => v ? () => {
console.log("hello");
return () => c();
}
: () => {
console.log("goodbye");
return () => exit(c);
}
);
}
All in one so you can try it:
const queue = [];
function trampoline() {
while(queue.length) {
let promise = queue.pop();
while (promise) {
promise = promise();
}
}
}
function spawn(c) {
queue.unshift(() => c(true));
return () => c(false);
}
function exit(c) {
return null;
}
function x(c) {
return () => spawn(
v => v ? () => {
console.log("hello");
return () => c();
}
: () => {
console.log("goodbye");
return () => exit(c);
}
);
}
queue.push(() => x(() => null));
trampoline();
Prints both hello and goodbye.
Guessing how javascript works
I'm going to finish off by going a bit hand-wavy and take a few guesses about how Javascript may be working "under the hood". As I understand it javascript is entirely event driven. it has both a thread queue and a thread pool. When you create a promise in javascript you are effectively spawning a new thread and putting it on the active thread queue where in time it will run. However when a thread is about to perform a blocking operation like i/o the operation will be initiated asynchronously and the thread will be removed from the active queue and placed instead in the thread pool, keyed by the file descriptor or other event id that it is waiting on.
When there are no active threads on the thread queue, the trampoline will return, but only to the main event loop which will then do a select or similar for any pending i/o or timers. As an input or output becomes readable or writable, or a timer event fires, select() will return its descriptor and that can be used to locate the associated thread dealing with this event in the pool. The thread (or threads if select() returned multiple descriptors) are removed from the pool and placed back on the active queue and the trampoline is re-invoked.
When there are no active threads on the queue and no threads in the thread pool, the Javascript process terminates.
Use in Production
One last little gasp, I said right at the start that I thought the subject both absolutely fascinating and totally useless at the same time, however I did get to use continuations in a meaningful and appropriate way once, a few years ago.
I was working for a major online video provider, and was tasked with parallelising a client library that talked to their API.
Basically what the client library was doing was making a single request to the API for a list of films, and then iterating over that list making blocking sequential requests to the API for details of each film. The library was written in Perl so did not have anything like Javascript's promises.
While this doesn't sound too difficult on paper (just make the calls asynchronously and register callbacks to handle the responses) what really turned the assignment into a poisoned chalice was that the loop over the array of film ids and the actual http requests to fetch individual films were very distant from one another, literally several function calls apart. so within the loop the code would do some preparation of the request, call a function to get the data then post-process that data and store the result. The called function would in turn do some pre-processing, call another function with the further modified data, post-process the result and return it, and so on down a long chain of function calls finally terminating at the actual http request.
In order to make those requests in parallel I re-wrote the loop and the chain of function calls in to CPS, then registered the continuation that would otherwise be passed to the actual http request (which wasn't our code and doesn't take a continuation) as the callback to invoke when the request completed.
The result was not entirely pretty, but short of a complete re-write it got the job done.

